


大规模训练解决方案
算力通过提升AI算力基础设施密度,优化算力调度,提升集群高速互联
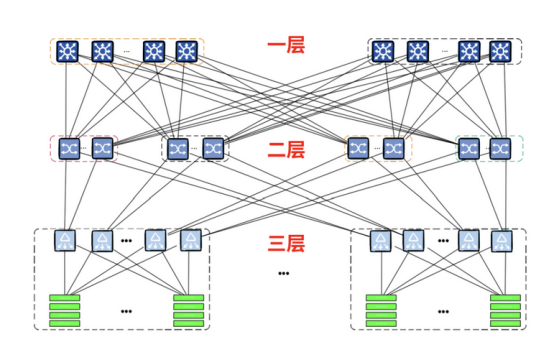
针对大模型大规模训练,猿界算力为解决大模型训练过程中,算力组网瓶颈、算力资源利用率低,算法工程师与算力匹配难、资源分配不灵活、资源分散难以管理等、猿界算力针对大规模模型训练多个阶段提供了不同的解决方案,我们的解决方案包括以下几个方面:
1. 高性能计算硬件集群:使用高性能的计算硬件组网算力集群,如GPU、TPU等 ,以满足大模型训练对计算能力的极高要求。 例如,搭载NVIDIA的GPU,如 A100、A800、H100、H800等 ,具有强大的并行计算能力 ,可以加速神经网络的训练过程。
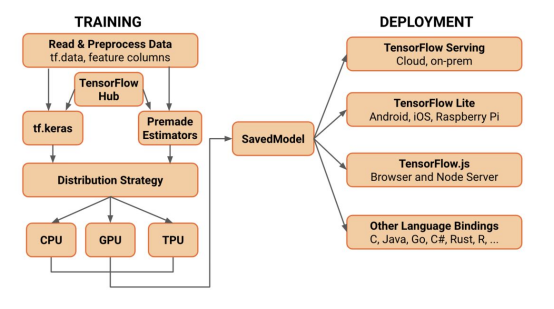
2. 分布式计算框架:利用分布式计算框架 ,如 TensorFlow、PyTorch、Onflow等 ,将训练任务拆分为多个子任务 ,分配到多个计算节点上,以实现并行计算 ,提高训练效率。同时,分布式计算框架可以对计算节点进行负载均衡 ,使得各个节点的计算资源得到充分利用。
3. 弹性计算资源调度:构建弹性计算资源调度系统 ,根据训练任务的需求 ,动态分配计算、存储、网络等资源。例如,百度的百舸平台提供了弹性计算资源调度功能 ,可以根据任务需求自动调整资源分配 ,以提高训练效率。
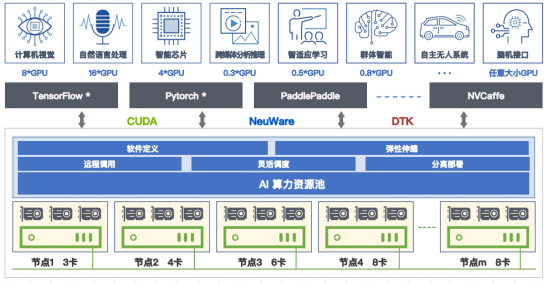
4. GPU算力资源池化:针对AI算力通过虚拟化形成软件定义的资源池,按需分配与调度, 提高资源利用率,降低成本。针对模型开发训练场景,整合算法、算力、数据,构建一体化平台,提高人员效率,缩短开发周期。
5.集群优化调度策略: 采用高效的集群优化调度策略 ,如 Hadoop YARN、Apache Mesos 等 ,可以实现对计算节点 的自动化调度和管理 ,提高集群的利用率和模型训练效率。
6.异构计算资源融合:将不同类型的计算资源 (如 GPU、FPGA、CPU 等) 进行融合 ,形成一个统一的计算平台,以满 足大模型训练对多样化计算资源的需求。例如 ,浪潮信息推出的 ALLin 一体机 ,将GPU、FPGA 等异构计算资源进行融合 ,提高了计算性能和训练效率。

方案优势
01
统一整理
建立客户资源库,资料统一整理
02
内外协同
销售全周期管理,内外协同
03
方便智能
移动应用管理,方便智能
04
综合分析
客户统计报表,综合分析
05
统一整理
建立客户资源库,资料统一整理
06
内外协同
销售全周期管理,内外协同
07
方便智能
移动应用管理,方便智能
08
综合分析
客户统计报表,综合分析






